前項では配列のインデックシングについて学びました。ここで解説する配列のスライスは、インデックシングを応用して、ベクトルや行列などのデータを任意の場所で分割することを言います。
これは機械学習で入力変数 \(x\) と出力変数 \(y\) を分けたり、教師データと訓練データを分けたりするためにほとんど必ず使わるテクニックですので、しっかりと学んでおきましょう。
当ページで学ぶこと
- NumPy配列のスライシングの方法
配列のスライスとは
配列のスライスとは、インデックス番号を活用して、配列の任意の範囲の要素を取り出すことを言います。
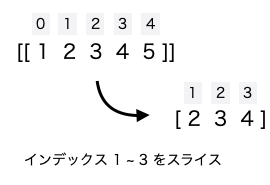
機械学習やデータ・サイエンスでは必ず使うものであり、 [開始位置 : 終了位置] というようにスクエア・ブラケットで取り出す範囲を指定することで実行します。このとき、開始位置のインデックスの要素はスライシングに含まれますが、終了位置のインデックスの要素は含まれないという点を覚えておいてください。
それでは例を見て、使い方をしっかりと抑えておきましょう。
配列のスライシング
ここではベクトルデータ(1次元配列)と行列データ(2次元配列)のスライシングについて、実際のコードを見ながら解説していきます。特に行列データのスライシングは、実務上、非常に頻繁に活用するものなので必ず確認するようにしてください。
それでは始めましょう。
ベクトル(1 次元配列)のスライシング
ベクトルの場合はインデックス番号が列方向しかないので、スライシングは非常に簡単です。上でも触れましたが、 [開始位置 : 終了位置] というようにスクエア・ブラケットで範囲を指定してスライスします。
以下のベクトルを例に見てみましょう。
# NumPyのインポート
import numpy as np
# 10列のベクトルを作成
data = np.array([1,2,3,4,5,6,7,8,9,10])
print(data)
まず [0:1] とスライスすると、インデックス 0 の要素だけをスライスします(スライスは開始位置の要素は含み、終了位置の要素は含まないことを思い出してください)。
# インデックス 0 以上 1 までをスライシング
print(data[0:1])
[1:4] と指定すると、インデックス 1 から 3 の要素をスライスします。
# インデックス 1 以上 4 までをスライシング
print(data[1:4])
終了位置を指定しない場合は、開始位置以降の要素をすべてスライスします。
# インデックス 7 以上をスライシング
print(data[7:])
スライシングには負のインデックス番号を指定することも可能です。
# 負の値のインデックスでスライシング
print(data[-4:-2])
2 次元配列のスライシング
2 次元配列のスライシングは機械学習でもっともよく使うものの一つです。2 次元配列のスライシングでは、[行のスライスの指定, 列のスライスの指定] というようにスクエア・ブラケットの前半で行要素をスライスし、カンマで区切って後半で列要素をスライスします。
特にここでは以下の 2 つのスライシング・テクニックを解説します。これらは必ず覚えておきましょう。
必ず使う 2 つのスライシング・テクニック
- 行列データを入力変数と出力変数に分割するテクニック
- 行列データを訓練データと教師データに分割するテクニック
- データを入力変数と出力変数に分割する
ロードしたデータを、入力変数 \(X\) と出力変数 \(Y\) に分割するのは、よく行うことの一つです。その場合、入力変数を取り出すには [:, :-1] とスライスし、出力変数を取り出すには [:, -1] とスライスします。
例として以下をご覧ください。まず最後の列の要素が出力変数 \(Y\) で、他の列の要素が入力変数 \(X\) のデータ行列を作成します。
# NumPyのインポート
import numpy as np
# 行列を作成
data = np.array([
[1,2,3,10],
[4,5,6,20],
[7,8,9,30]
])
print(data)
このデータの中から入力変数 \(X\) だけをスライスする場合は、次のように書きます。
# 入力変数をスライス
print(data[:,:-1])
そして出力変数 \(Y\) をスライスする場合は、次のように書きます。
# 出力変数をスライス
print(data[:, -1])
なぜ、この書き方でこれができるのか考えてみてください。その際は、当ページ末に掲載している「一緒に読んでおきたいページ」が役に立ちますので、ぜひご覧ください。
- データを訓練データと教師データに分割する
ロードしたデータを訓練データと教師データに分割することもよく行うことの 1 つです。その場合は訓練データを data[:split, :]、教師データを data[split:, :] として区切るやり方がよく使われます。
例として以下のコードをご覧ください。まずは行列データを作成します。
# NumPyのインポート
import numpy as np
# 行列データを作成
data = np.array([
[1,2,3],
[4,5,6],
[7,8,9],
[10,11,12],
[13,14,15]
])
print(data)
以下のように書くと、このデータを訓練データと教師データに分けることができます。
# 訓練データと教師データをスライス
split=3
train, test = data[:split, :],data[split:, :]
print(train, "\n")
print(test)
なぜ、この書き方でこれができるのか考えてみてください。以下のページは、考える上でとても役に立ちますので、ぜひご確認ください。
一緒に読んでおきたいページ