ここまでで NumPy でベクトルや行列などのデータを作成したり、作成したデータを結合したりする方法を見てきました。ここでは作成した配列を扱う上で土台となる知識である「インデックス」という概念について解説します。
早速見ていきましょう。
当ページで学ぶこと
- インデックスとは何か
- NumPy配列のインデックシングの方法
インデックスとは
インデックスとはデータを格納する際に、データのそれぞれの要素につける識別番号のようなものです。NumPyの配列のインデックスは、java や C♯、C++ などのプログラミング言語と同じです。先頭のインデックスを 0 として、順番に番号が振られていきます。
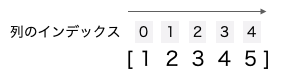
たとえば以下のベクトルデータの場合は、先頭から 3 つ目の要素にはインデックス番号 2 が割り振られています。
行列の場合は行ごと、列ごとに別々にインデックス番号が割り振られます。たとえば以下の行列データの場合、3 という値には行のインデックス番号は 0 、列のインデックス番号は 2 が割り振られています。

このように NumPy の配列の要素ごとに番号を割り振ること、そしてその番号のことを「インデックス」と言います。
インデックシング
インデックスされた番号を指定することで任意の要素を取り出すことを「インデックシング」と言います。方法は簡単です。任意の配列の後にスクエア・ブラケット [] で取得したい要素のインデックスを指定することで、その要素を取り出すことができます。
一度作ったNumPy配列のデータの要素の一つひとつは、インデックシングすることでアクセスすることができます。一つひとつ具体的に見ていきましょう。
ベクトル(1 次元配列)のインデックシング
1 次元配列の場合は、先頭のインデックスを 0 として、四角いブラケット [] で取得したい要素のインデックス値を指定します。
# NumPyのインポート
import numpy as np
# 1次元配列(ベクトル)を作成
data = np.array([1,2,3,4,5])
print(data)
# データのインデックシング
print(data[0])
なお Python では他の多くのプログラミング言語と違って、最後の要素を -1 として、負のインデックス値を指定することができます。
# 負の番号でのインデックシング
print(data[-1])
行列(2次元配列)のインデックシング
2 次元データのインデックシングは、[行のインデックス, 列のインデックス] の順番でカンマで区切って指定します。
通常、C 言語をベースとしたプログラミング言語は、[0, 1] というようにカンマで区切るのではなく、[0][1] というように四角ブラケットで区切りますが、Python はカンマで区切ることができる点が異なります。
たとえば 3 行目 2 列目の要素のインデックシングは次のように行います。
# NumPyのインポート
import numpy as np
# 5行5列の行列の作成
data = np.array([
[1,2,3,4,5],
[6,7,8,9,10],
[11,12,13,14,15],
[16,17,18,19,20],
[21,22,23,24,25]
])
print(data)
# 3行目2列目のデータのインデックシング
print(data[2][1])
次のようにインデックスを指定すれば、指定の行の要素だけをインデックシングすることができます。
# 行の要素だけをインデクッシング
print(data[2])
以上が実務上で押さえておくべきインデックシングの方法です。
なお以下のページでは、インデックスについてさらに細かいテクニックを解説していますので、ご興味がある方はぜひご覧ください。
一緒に読んでおきたいページ