
このページでは、Pythonのfor文による繰り返し処理(forループ)についての基本と、覚えておくと処理の幅が広がる関数を解説します。
1. for文とは
for文は「あるオブジェクトの要素を全て取り出すまで処理を繰り返す」というコードを書くときに使うプログラミング構文です。同じく繰り返し処理を作るものにwhile文がありますが、そちらは「ある条件が真(True)の間、指定の処理を繰り返す」というものです。
この違いから、それぞれ「forループ」「whileループ」と呼ばれています。while文は「Pythonのwhile文のbreakを使ったループの中断条件の作り方」で解説しているので、for文と対比しながらご確認ください。
1.1. for文の繰り返し処理
for文の繰り返し処理の最も基本的な使い方は、文字列やリスト、タプル、辞書、セットなどのイテラブル(=要素を一つずつ取り出すことができるオブジェクト)から要素を取り出すというものです。
Pythonではイテラブルから要素と取り出す操作を頻繁に行いますが、for文を使えばイテラブルのデータサイズや、どのように実装されているかを知らなくても、各データの要素を操作することができるのです。
早速、基本的な書き方を見てみましょう。
''' イテラブルから要素を一つずつ取り出す時の書き方 '''
for 変数名 in イテラブル: # ←末尾にコロン「:」
処理文 # 処理文の前に半角スペース4つ
まず変数名は一時的なもので任意の名称で構いません。一行目の末尾のコロン「:」は忘れがちなので注意しましょう。二行目に処理文を書くのですが、その前には半角スペースを4つ空ける必要があります。
このコードを書くと、Pythonの内部では下図の処理が実行されます。イテラブルの要素を全て取り出したら繰り返し処理(forループ)を終了します。
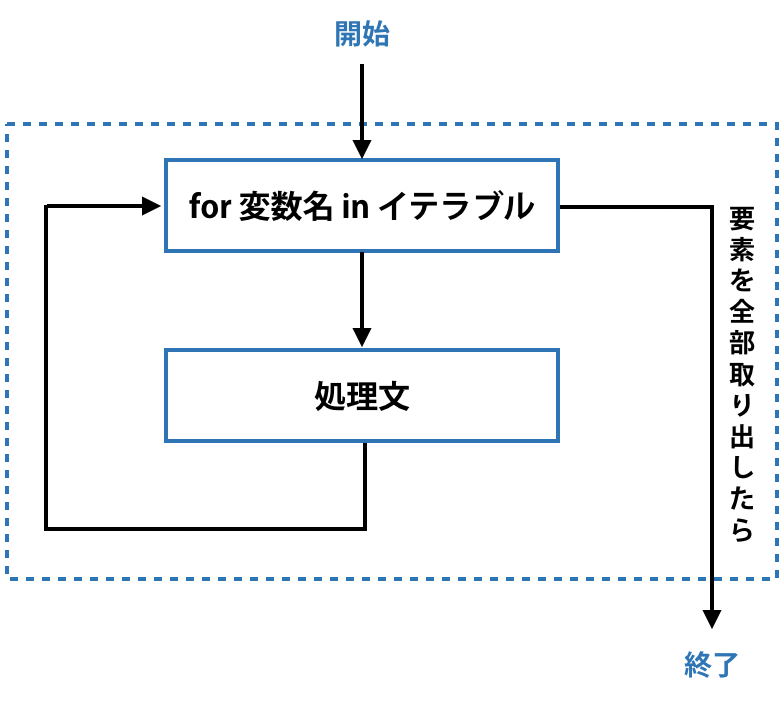
実例を見ていきましょう。
1.1.1. リスト等の要素の取得
それではfor文の繰り返し処理を使ってリストから一つずつ要素を取り出して出力してみましょう。次のコードをご覧ください。
fruits = ['apple', 'banana', 'cherry', 'durian']
for item in fruits:
print(item)
リストの要素が一つずつ取り出されて「print(item)」で出力されていますね。
この時、Pythonの内部で起きている処理は次のようになっています。まず、変数itemにリストの最初の要素である’apple’が代入され、それがprint(item)で出力されます。その後、最初に戻って今度は変数itemに’banana’が代入されprint(item)で出力されます。続いて、’cherry’が、そして’durian’が変数itemに代入され、それぞれ出力されます。
最後に変数itemには’durian’が代入されている状態でforループを終了しているので、処理の後に変数itemを展開すると’durian’が出力されます。
print(item)
二重リストからfor文で要素を取り出す場合も見てみましょう。次のようになります。
nums = [[1, 2, 3], [10, 20, 30], [100, 200, 300]]
for i in nums:
print(i)
内側の要素を全て取り出すには、forループを2回まわします。「for i in nums:」で外側の要素を、変数 i に代入し、「for k in i:」で変数 i に代入した要素をひとつずつ k に代入しています。
for i in nums:
for k in i:
print(k)
「Pythonのリストからの要素の取り出し」では、さらに詳しく解説しています。
余談ですが、イテラブルから要素を取り出すために次のようにwhileループで処理するのもPythonのコードとしては決して間違いではありません。
fruits = ['apple', 'banana', 'cherry', 'durian']
count = 0
while count < len(fruits):
print(fruits[count])
count += 1
しかしイテラブルから一つずつ要素を取り出すには、for文を使う方がより「Pythonらしい」良い書き方です。
さて、文字列やタプル、セットの場合もこれと全く同じように要素を取り出すことができます。文字列の場合は1文字ずつ文字が取り出されます。
''' 文字列 '''
word = 'dog'
for letter in word:
print(letter)
''' タプル '''
tuple = ('日', '月', '火')
for day in tuple:
print(day)
''' セット '''
set = {'macユーザー', 'windowsユーザー'}
for user in set:
print(user)
1.1.2. 辞書の要素の取得
forによる反復処理で辞書から要素を取り出したい場合は、他のイテラブルと少し勝手が違います。辞書ではキーと値が1セットで1つの要素であり、キーが値を保持しているからです。
そのためfor文を普通に書けばキーを取り出します。値を取り出すにはvalues()を、両方取り出すにはitems()を併用する必要があります。
dict = {'A':'apple', 'B':'banana', 'C':'cherry'}
# 普通に書くとキーを取り出す
for key in dict:
print(key)
# 値を取り出す(values()を使う。)
for value in dict.values():
print(value)
# 両方取り出す(items()を使う。)
for items in dict.items():
print(items)
キーと値を両方取り出した場合はタプル型で出力されていますね。タプルの各要素は、以下のように個別の変数に一度に代入することができるのはご存知でしょうか(実際は辞書以外でも全てのイテラブルで可能です)。
letter, name = ('A', 'apple')
print(letter)
print(name)
これを利用して、for文で辞書のキーと値を両方取り出したい場合は、次のように変数を2つ利用する書き方も可能です。
''' 辞書のキーをletterに、要素をnameに一つずつ代入して出力しています。 '''
for letter, name in dict.items():
print(letter, 'がつく果物には', name, 'があります。')
これも知っておくと処理の幅が広がります。
なお、これらについては「Pythonの辞書(dict)のforループで要素を取り出す方法」でも解説しています。
1.2. for文の条件分岐
for文でもwhile文と同じように「条件Aに該当する時はこうする、別の条件Bに該当する時はああする」というように条件分岐を書くことによって、イテラブルからどのように要素を取り出していくのかを細かく設定していくことができます。
その条件分岐の書き方を一つずつ見ていきましょう。
なお条件分岐を書くには、if文を理解している必要があります。「Pythonのif文を使った条件分岐の基本と応用」もご確認ください。
1.2.1. breakで繰り返し処理を中断
何かが起きるまでfor文による繰り返し処理を続けたいが、何かが起きた場合には反復処理を中断したいという場合はbreak文を使います。下図のようにbreak文に書いた中断条件に該当するとforループを終了します。
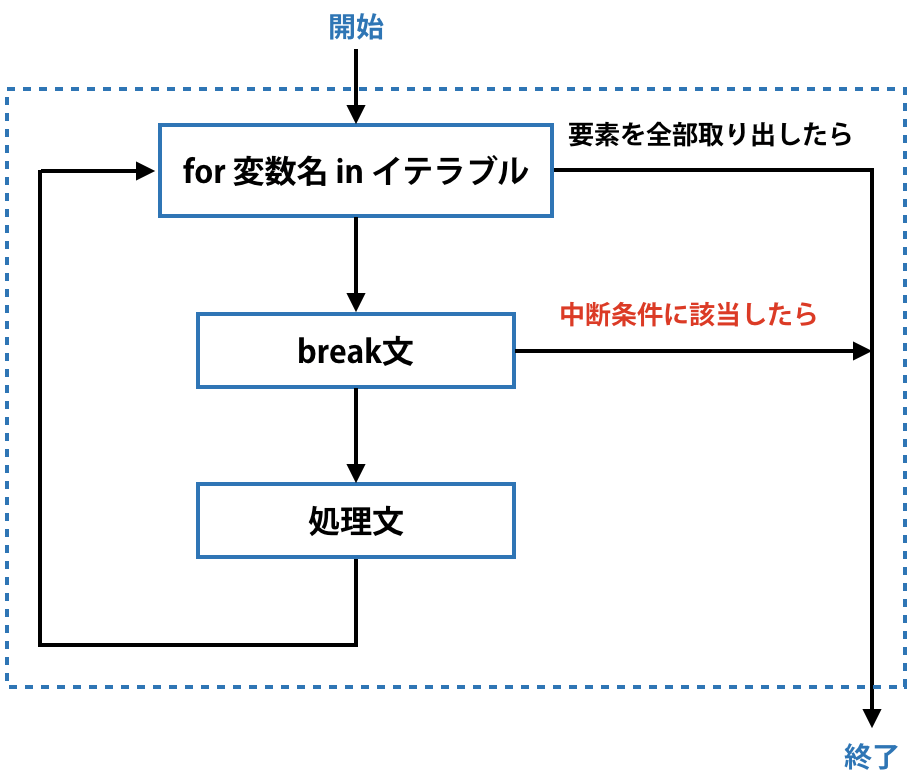
次のコードをご覧ください。
nums = [1, 2, 'a', 3, 4]
for num in nums:
if not isinstance(num, int):
print(f'{num} は数値ではありません。')
break
print(num)
リストnumsから一つずつ要素を取り出しますが、if文とbreak文で中断条件を一つ書いています。「取り出した要素の型が整数型(int型)でない場合」という中断条件です。出力結果を見るとリスト内の文字列要素’a’が取り出された時点で反復処理を中断していますね。
なお、コード内で使っているisinstance()は、オブジェクト(インスタンス)の型を判定する関数です。詳細は「Pythonの変数の型を調べる方法」で解説しています。
そしてbreakについては「Pythonのforループのbreak(中断条件)」で、さらに詳しく解説しています。
1.2.2. continueで特定の要素の処理をスキップ
for文による反復処理を行いたいが、特定の条件に該当する時はその処理をスキップしたい、または別の処理を行い次の要素の反復処理に移りたいという時はcontinue文を使います。下図のようにcontinue文に書いた条件に該当したら、その処理をスキップして、次の要素の反復処理に移ります。
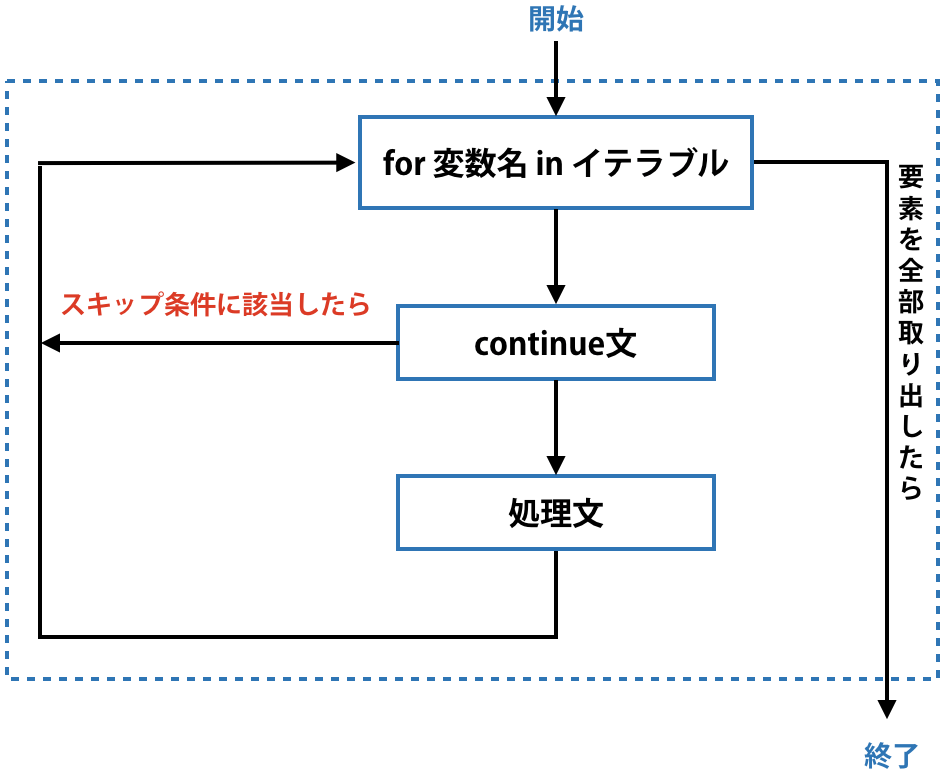
次のコードをご覧ください。
nums = [1, 2, 'a', 3, 4]
for num in nums:
if not isinstance(num, int):
continue
print(num)
リストnumsから一つずつ要素を取り出していますが、if文とcontinue文でスキップ条件を書いています。スキップ条件は「取り出した要素が整数型(int型)でない場合」です。
出力結果を見ると、リスト内の要素の’a’が取り出された時に処理をスキップしていますね。そして、次の要素である3の処理に移っています。
なお、if文とcontinueの間にスキップした場合のみの処理を書くこともできます。以下のコードと上のコードを見比べてみましょう。
nums = [1, 2, 'a', 3, 4]
for num in nums:
if not isinstance(num, int):
print('スキップしました。')
continue
print(num)
スキップした時は別の処理がされていますね。「Pythonのforループでのcontinue」ではさらに詳しく解説しています。
1.2.3. elseで繰り返し処理が正常に終了後の処理
for文による繰り返し処理(forループ)が正常に終わった後に特定の処理を行いたい場合はelse文を使います。
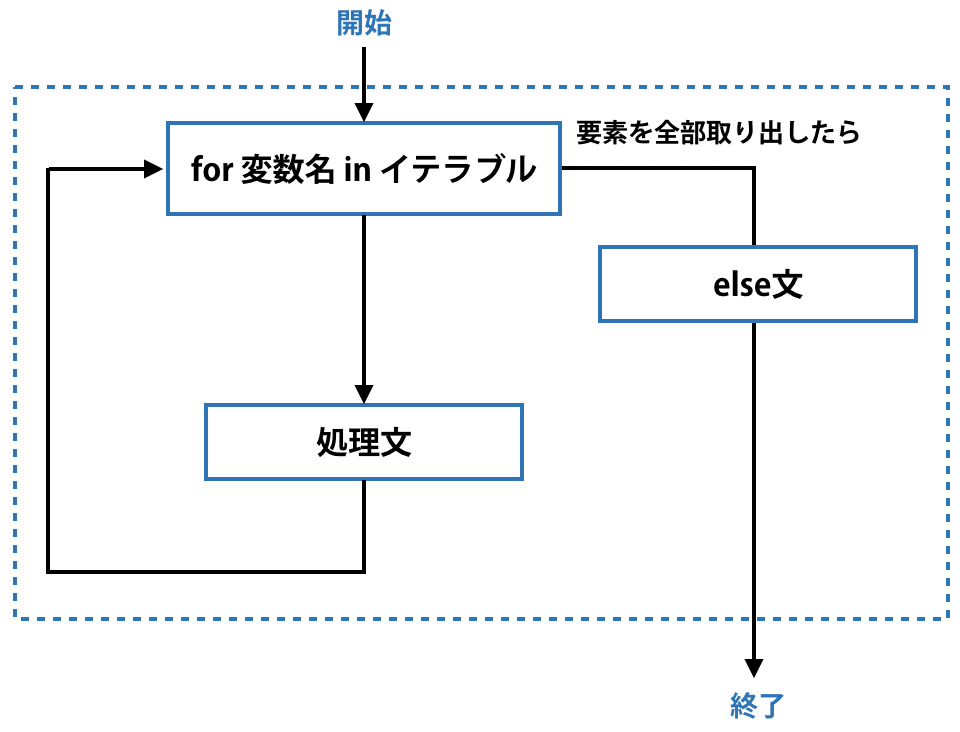
次のコードをご覧ください。
nums = [1, 2, 'a', 3, 4]
for num in nums:
print(num)
else:
print('ループ処理が正常に終了しました。')
このようにループが正常に終了した場合にelse文に書いた処理が実行されます。ただしfor文の後に同じ処理を書けば、次のように全く同じ出力結果になります。
nums = [1, 2, 'a', 3, 4]
for num in nums:
print(num)
print('ループ処理が正常に終了しました。')
これではelse文には意味がないように思えてしまいます。実はelse文はbreak文と組み合わせて使うと本領を発揮します。そうすると下図のように、breakした時はそのまま中断し、breakしなかった時はelse文の処理を実行するというコードになります。
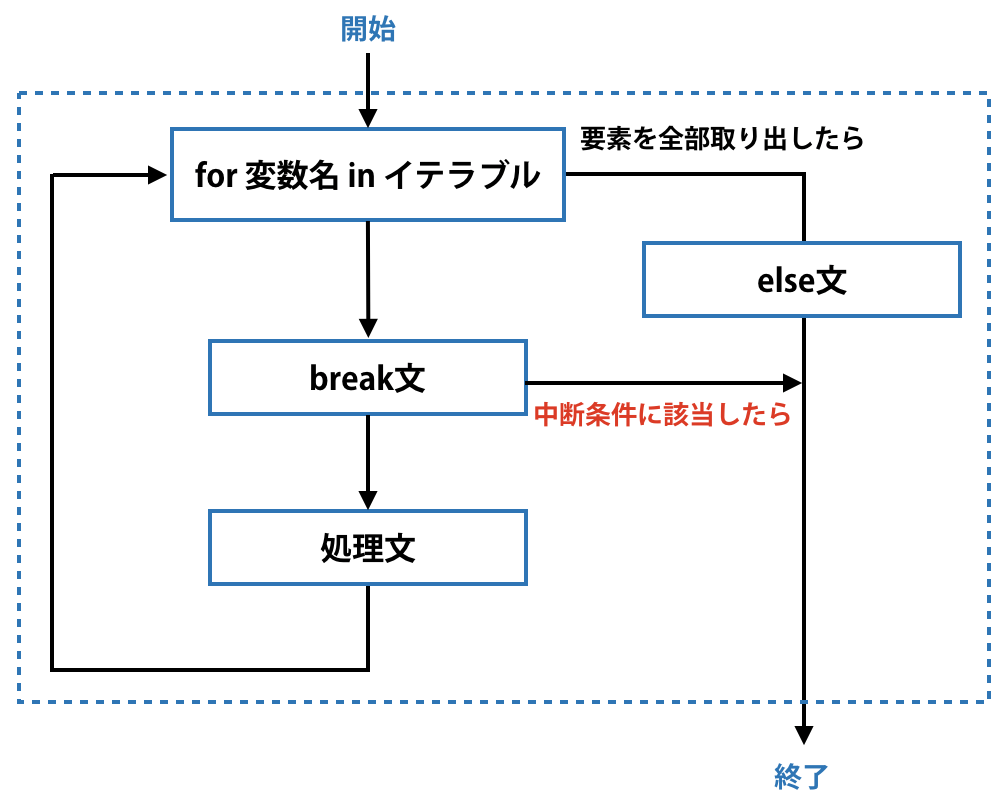
次のコードを見てみましょう。これはbreak条件に該当しているので処理が中断されてelse文は実行されていません。
nums = [1, 2, 'a', 3, 4]
for num in nums:
if not isinstance(num, int):
print(f'{num} は数値ではありません。')
break
print(num)
else:
print('ループ処理が正常に終了しました。')
一方で、breakの中断条件に引っかからなかった場合はelse文の処理が実行されます。
nums = [1, 2, 3, 4, 5]
for num in nums:
if not isinstance(num, int):
print(f'{num} は数値ではありません。')
break
print(num)
else:
print('ループ処理が正常に終了しました。')
このようにelse文を入れておくことで、for文の反復処理が正常に終了したかどうかを確認することができるのですね。なおcontinue文の条件に該当して、要素の処理の一部をスキップした場合でもfor文は要素の最後まで取り出すので、最後にelse文が実行されてforループを終了します。
elseについては「Pythonのfor文のelseの使い方」でさらに詳しく解説しています。
1.2.4. break・continue・elseの組み合わせ
break・continue・elseを全て組み合わせて使うと、次のような処理経路になります。
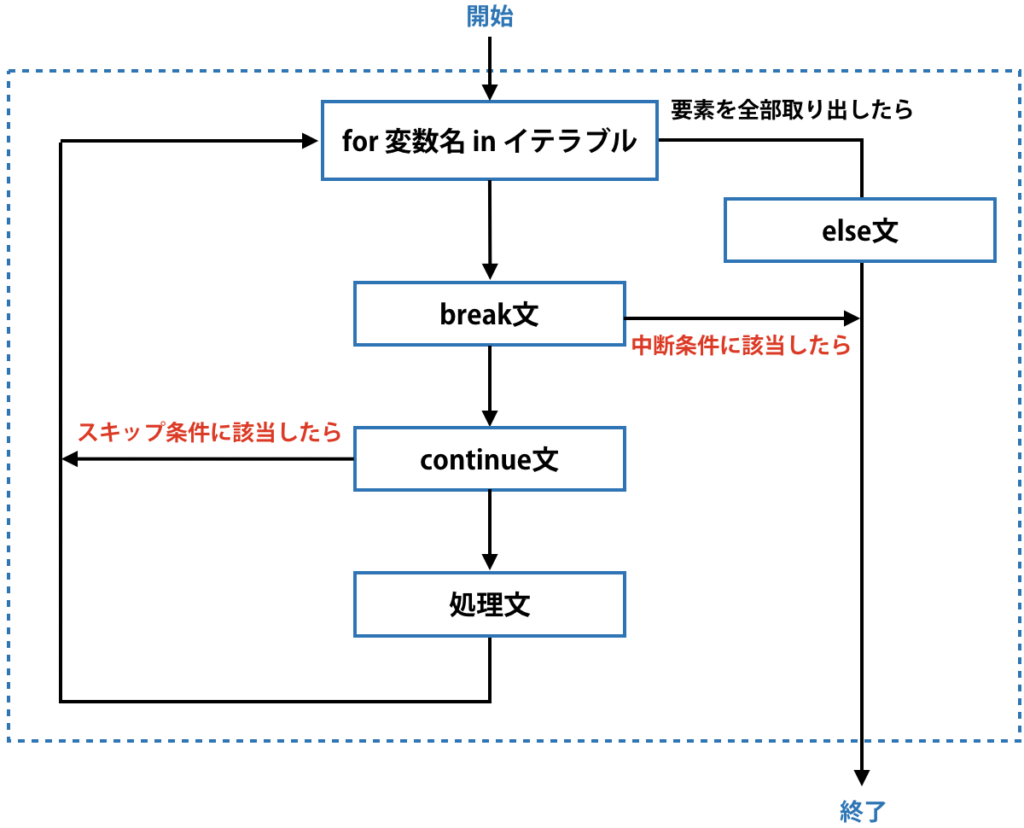
サンプルコードを見てみましょう。
次のコードでは、中断条件に該当する要素(数値ではない場合)はなく、スキップ条件に該当する要素(浮動小数点数の場合)があるので、一度だけ処理をスキップした上で、else文が実行され、forループが終了しています。
nums = [1, 2, 3.5, 4, 5]
for num in nums:
if not isinstance(num, (int, float)):
print(f'{num} は数値ではありません。')
break
elif isinstance(num, float):
print(f'取り出した数字{num}は浮動小数点数なのでスキップします。')
continue
print(num)
else:
print('ループ処理が正常に終了しました。')
次のコードでは中断条件(要素が文字列である場合)に該当しているので、そこでelse文は実行されずにforループが終了しています。
nums = [1, 2, 3.5, 'a', 4]
for num in nums:
if isinstance(num, (str)):
print(f'{num} は数値ではないので処理を中断します。')
break
elif isinstance(num, float):
print(f'取り出した数字{num}は浮動小数点数なのでスキップします。')
continue
print(num)
else:
print('ループ処理が正常に終了しました。')
それぞれの処理経路をしっかりと把握しておきましょう。
2. for文の幅を広げる便利な関数
2.1. range関数で指定回数の繰り返し処理を行う
for文とrange関数を組み合わせて使えば、任意の回数の繰り返し処理を行うコードを、コンピューターのメモリを使い切ってしまうことなく書くことができます。
例えば、もし、同じ処理を任意の回数繰り返し行いたい場合に、次のように律儀に一つずつ処理を書いていたのでは、コードの行数も長くなり非常に読みにくいコードになってしまいます。
print(1)
print(1)
print(1)
print(1)
print(1)
この例では、まだ繰り返し回数が5回なのでマシですが何百回も何千回も繰り返し処理を行いたい場合は、とても機能的とは言えません。しかしfor文とrange関数を使うと、それをたった2行で表すことができます。
for i in range(5):
print(1)
こちらの方がはるかに簡潔で読みやすいですね。
なおrange関数は、以下のように連続した数値を生成する関数で、返り値はrange型オブジェクトです。そのrange型オブジェクトをlist関数にかけると、0からn-1までの連続したリストが生成されます。
print(range(10))
print(type(range(10)))
print(list(range(10)))
range関数の利点として、必要な時に要素を生成するので、コンピュータのメモリを使い尽くしてプログラムをクラッシュさせることなく、非常に大きな回数の繰り返し処理を行うコードを書くことができるという点があります。
例えば、もしrange関数がなかったら、同じ処理を1万回繰り返すなら、要素が1万個あるリストを作らなければなりません。そして繰り返し処理の間、コンピュータのメモリは、そのデータを全て格納しなければなりません。しかしrange関数の場合は実際に要素が1万個あるリストを作るわけではなく、処理1回ごとに要素を生成するのでメモリに負担をかけないのです。
そのため次のような繰り返し回数が大きなコードも手軽に書くことができます。0から1,000,000の数字を全て合計するものです。100万回という非常に大きな回数の繰り返し処理ですが、コンピュータに負担をかけることなく実行することができます。
sum = 0
for i in range(1000001):
sum += i
print(sum)
もちろん、range関数による繰り返しの場合でも、breakやcontinue、else文を使うことができます。次のコードでは変数iが500000より大きくなった時に繰り返し処理を中断し、変数iが10000より大きく20000より小さい場合は全て処理をスキップしています。そして最後にfor文の外で中断までの数値の合計を出力しています。
sum = 0
for i in range(1000001):
if i > 500000:
break
elif 10000 < i < 20000:
continue
sum += i
print(sum)
こうした膨大な繰り返し回数の処理を、いちいちリストを用意して行うのは大変ですが、range関数を使うと素早くかつ簡潔に行うことができます。
なお、次のようにrange関数には第三引数まで指定することができます。
range(開始位置, 終了位置, ステップ)
これを使うとさまざまな連続した数値を作ることができます。以下は、2から10までの偶数の数値を作ったものです。
for i in range(2, 11, 2):
print(i)
ステップでマイナスの値を指定すれば、逆順の数値を作ることもできます。
for i in range(5, 0, -1):
print(i)
以下のページではrange関数の細かい使い方や、range関数を使った繰り返し処理、Python2とPython3での違いなどの重要な点を解説しているので、ぜひ一度目を通しておいてください。
2.2. zip関数で複数イテラブルの要素を同時取得
複数のイテラブルの要素を複数の変数に代入して、まとめて処理したい場合はzip関数を使います。次のコードをご覧ください。
players = ['山田', '佐藤', '鈴木']
scores = [90, 70, 80]
for player, score in zip(players, scores):
print(player, score)
for文の中で、リストplayersの要素は変数playerに代入し、リストscoresの要素は変数scoreに代入し、それを反復して出力しています。この方法を使うと、次のコードのような処理を行うことができます。
for player, score in zip(players, scores):
print(f'{player}選手の得点は{score}点です。')
zip関数の引数には数の上限なくイテラブルを渡すことができます。次の例では、辞書とリストとタプルを同時に展開して処理しています。
players = {'山田':'20才', '佐藤':'18才', '鈴木':'25才'}
scores = [90, 70, 80]
places = ('東京', '大阪', '福岡')
for player, age, score, place in zip(players, players.values(), scores, places):
print(f'{place}代表の{player}選手{age}の得点は{score}点です。')
2.3. enumerate関数で要素とインデックスを同時取得
enumerate関数を使うと、イテラブルの要素とインデックス番号を同時に取得することができます。
fruits = ['Apple', 'Banana', 'Cherry']
for i, name in enumerate(fruits):
print(i, name)
このようにfor文の最初に書いた変数’i’にインデックス番号が代入され、次に書いた変数’name’にリストの要素が代入されます。
第二引数で開始番号を指定すると、インデックス番号をその番号から始めてくれます。
fruits = ['Apple', 'Banana', 'Cherry']
for i, name in enumerate(fruits, 10):
print(f'{name}は{i}番の要素です。')
なお、これはタプルでも可能ですが、辞書ではできません。なぜなら辞書はキーによって、それに対応する値を保持するからです。
また、enumerate関数とzip関数は次のように併用することができます。zip関数に相当する変数は、括弧()で囲む必要があります。
players = ['山田', '佐藤', '鈴木']
scores = [90, 70, 80]
for i, (player, score) in enumerate(zip(players, scores)):
print(f'{i}番の{player}選手の得点は{score}点です。')
これらは「Pythonのfor文でインデックス(index)を取得する方法」でさらに詳しく解説していますので、ぜひあわせてご確認ください。
2.4. reversed関数で要素を逆順で取得
reversed関数を使うとイテラブルの要素を逆から取得することができます。次のように書きます。
nums = [1, 2, 3, 4, 5]
for num in reversed(nums):
print(num)
enumerate関数の返り値であるenumerate型オブジェクトは、そのままではreversed関数に渡すことはできません。一度list関数でリスト化してから渡す必要があります。
fruits = ['Apple', 'Banana', 'Cherry']
for i, name in reversed(list(enumerate(fruits))):
print(i, name)
インデックスは昇順、イテラブルの要素は降順にしたい時は、イテラブルのみをreversed関数に渡します。
for i, name in enumerate(reversed(fruits)):
print(i, name)
zip関数の返り値のzip型オブジェクトも、そのままではreversed関数に渡せないので、list関数でリスト化して渡す必要があります。
players = ['山田', '佐藤', '鈴木']
ages = [20, 18, 25]
for player, age in reversed(list(zip(players, ages))):
print(player, age)
次のように書けばenumerate関数が生成するインデックス番号も、zip関数が生成する複数イテラブルの要素も、同時に逆順で取得することができます。
for i, (player, age) in reversed(list(enumerate(zip(players, ages)))):
print(i, player, age)
インデックス番号は昇順で、複数イテラブルを逆順にしたい場合は、zip関数のみreversed関数に渡します。
for i, (player, age) in enumerate(reversed(list(zip(players, ages)))):
print(i, player, age)
2.5. itertools.product関数で多重ループの作成
Pythonでは多重のforループは次のように書きます。インデント(半角空白4つ)でブロックを表すので、外側のループの下にインデントを入れて内側のループを書くのです。
list1 = [1, 2, 3]
list2 = [1, 2]
for i in list1:
for j in list2:
print(f'外側ループ{i}回、内側ループ{j}回')
この処理は下図のようになっています。外側のループで最初の要素1を取り出したら内側のループで全ての要素1と2を取り出し、また外側のループに戻ります。今度は外側のループで2を取り出したらまた内側のループで要素1と2を取り出します。最終的に外側のループで要素を全て取り出したらループ終了です。
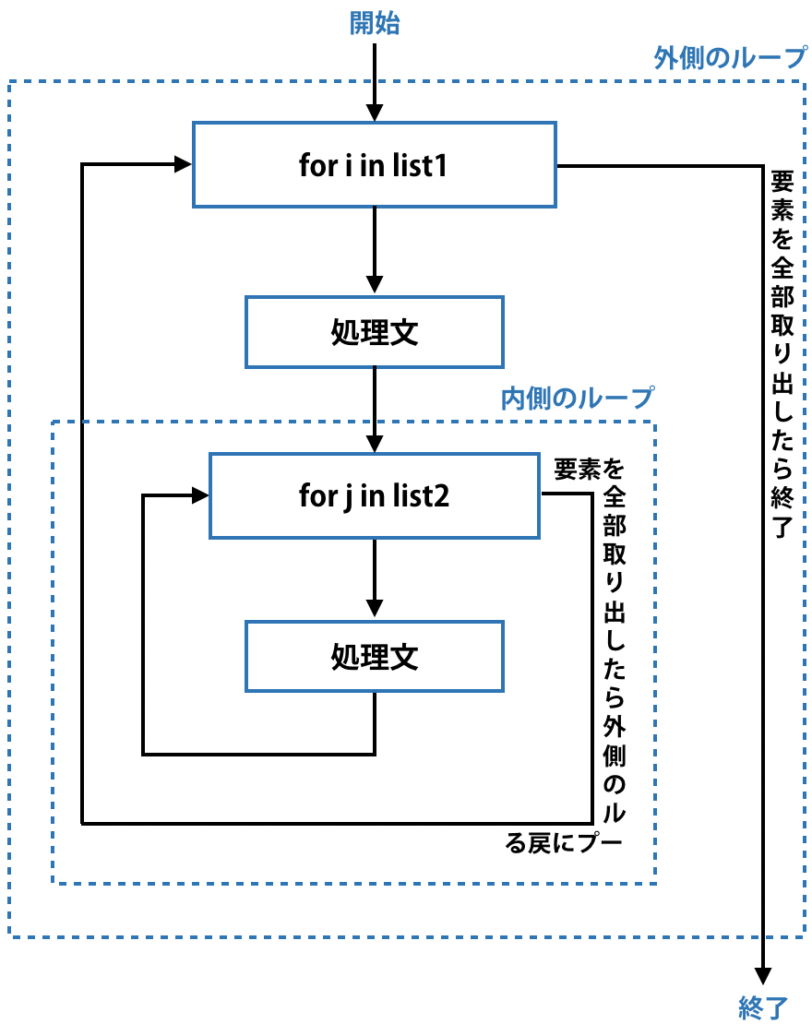
これと同じ結果は、itertoolsモジュールのitertools.product()関数を使えば、より簡潔なコードで得ることができます。
import itertools # 最初にitertoolsモジュールを読み込む必要があります。
list1 = [1, 2, 3]
list2 = [1, 2]
for i, j in itertools.product(list1, list2):
print(f'外側ループ{i}、内側ループ{j}')
三重以上のループ処理も可能です。
list3 = [1]
for i, j, k in itertools.product(list1, list2, list3):
print(f'外側{i}、真ん中{j}、内側{k}')
ただし多数の要素があるリストを処理する場合、itertools.product関数は処理速度が遅いので、コードの可読性との関係も考えて使い分けられるようになるとベストですね。
3. リスト内包表記
リスト内包表記は「Pythonらしい」書き方で、リストを簡潔な式で書くことができるものです。for文を理解するとリスト内包表記も理解できるようになります。
比較例として、例えばfor文で要素を生成してリストを作るとしたら、次のようなコードになります。
squares = []
for i in range(1, 6):
squares.append(i**2)
print(squares)
これと同じことをリスト内包表記では、より簡潔に書くことができます。書き方は次の通りです。
[式 for 変数名 in イテラブル]
実際に見てみましょう。
squares = [i**2 for i in range(1, 6)]
print(list)
条件分岐を書くこともできます。
squares = [i**2 for i in range(1, 6) if not i ==3]
print(squares)
odd_squares = ['skip' if i % 2 == 0 else i**2 for i in range (1, 11)]
print(odd_squares)
こうしたリスト内包表記については、「Pythonのリスト内包表記の基本的な使い方」で、さらに詳しく解説しているのでぜひご確認ください。
4. まとめ
for文とは「あるオブジェクトの要素を全て取り出すまで処理を繰り返す」というforループを書くための構文です。これを使うと、イテラブルから効率的に要素を取り出すことができます。
繰り返し処理の途中で中断条件を入れたいならbreakを、スキップ条件を入れたいならcontinueを、forループが正常に終了した場合の処理を入れたいならelseを入れることによって条件分岐を書くことができます。
また、range関数と組み合わせると、イテラブルの要素を取り出すのではなく、任意の回数の繰り返し処理を行うコードを簡単に書くことができます。
以上の点をおさえた上で様々な操作方法を一つずつ抑えていきましょう。





コメント